
PDF 文件是日常工作中最常見的檔案格式之一,不論是發票、合約、報告或是其他重要文件,大多都會以 PDF 形式儲存。然而,常見的狀況是我們可能要從這些 PDF 檔案抓取所需的文字或表格,再將其整合到其他文件中。
因此,這篇文章將介紹如何使用 Power Automate Desktop 來自動化抓取 PDF 中的文字及表格資料,以利後續的其他工作流程使用。
此處使用公開網站提供的 PDF 純文字檔案及 PDF 表格檔案作為示範,會分為兩個子流程進行內容抓取。
第一個情境是抓取 PDF 文字內容後,將文字內容擷取匯出至 Word 檔案,以進行下一步利用。(檔案原始樣貌如下圖)
第二個情境則是抓取 PDF 的表格檔案,並將這些表格內容擷取匯出至 Excel 檔案,再接續後續的利用。(檔案原始樣貌如下圖)
情境一流程腳本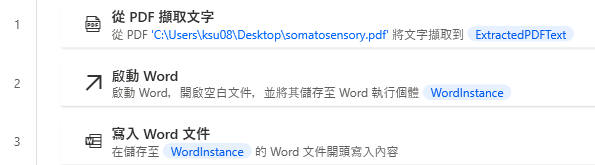
情境二流程腳本
此處使用的重點功能為「從 PDF 擷取文字」,步驟滿單純的,在左側動作欄找到 PDF 後,將「從 PDF 擷取文字」拉取至腳本區,接下來在 PDF 檔案選擇指定的檔案;要擷取的頁面則視需求決定範圍,此處以擷取全部作為範例。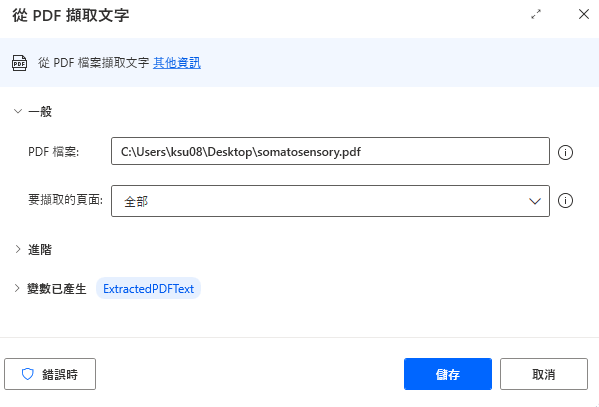
接著因為我們的目標是要把 PDF 的擷取文字抓出至 Word,因此從動作欄選擇「啟動 Word」、「寫入 Word 文件」。
直接建立一個新的空白 Word 文件,並在寫入 Word 文件該動作中「要寫入文件的內容」的欄位,填入 PDF 擷取文字該動作所生成的變數即可。
和上一個情境頗為類似,只是這次第一個選擇的動作是「從 PDF 擷取資料表」,同樣在 PDF 檔案選擇指定的檔案。要擷取的頁面一樣視需求決定範圍,此處以擷取全部作為範例。
接著先暫停停止拉下一個動作方塊,我們先讓這個擷取資料表的動作先運行看看,原因是現在的動作進行方式是擷取資料表,而非文字。因應每個 PDF 的格式不一樣,有可能會抓取到不只一個資料表,所以我們要先找到 RPA 幫我們抓取的資料表型態、位置在哪邊。
因此,我們先在這時按下執行,讓系統運作看看,接著觀察存取的表格變數內容。(參考以下影片運作方式)
透過觀察,我們可以看到表格內容存取在 DataTable 這個屬性中。
接下來,拉入「啟動 Excel」和「寫入 Excel 工作表」這兩個動作,需要特別注意的是在寫入 Excel 工作表的這個動作中,要特別在「要寫入的值」填上 %ExtractedPDFTables[0].DataTable% ,由於目標抓取的表格編號為 0,故要在填入表格變數後加上[0] ,並加上屬性 .DataTable。
「寫入模式」這次選擇於指定的儲存格;「資料行」、「資料列」分別填上 A 和 1,屆時資料就會從左上角的第一個儲存格開始填入。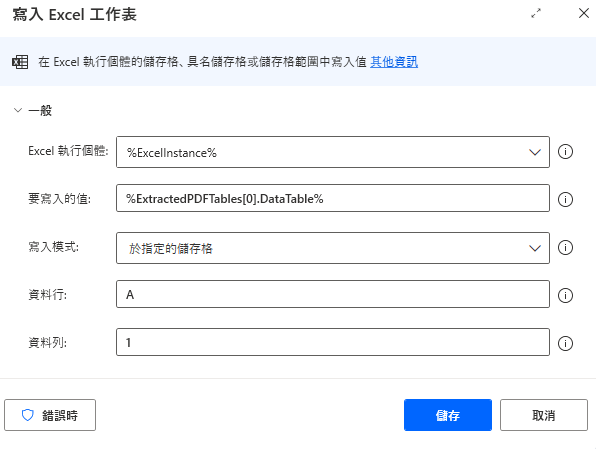
這篇文章中,我們示範了如何利用 Power Automate Desktop 的 PDF 擷取功能,從不同型態的文件中自動化萃取文字及表格資料,並將其導入到 Word 或 Excel 中。這樣的自動化流程不僅提高了處理效率,也增加了資料型態轉換的靈活度。
這只是 PDF 自動化處理的小小應用場景,下一篇文章同樣是 PDF 的主題,將會分享有關 PDF 資料合併及拆分檔案的作法。

 iThome鐵人賽
iThome鐵人賽